

2·
8 months agoInteresting experiment! Made me think of the book “how we learn: the new science of education and the brain”

Interesting experiment! Made me think of the book “how we learn: the new science of education and the brain”

As a French I’m insulted by this title :p
Before selling the 5, they should make it so one can buy the 4 x)
Thanks for sharing! I’ll have a look later it sounds great!
Any way to bypass the paywall for this article :)?
I always feel like research on coffee is inherently biased since 99% of scientists I know are hooked on coffee :p
That’s a fairly terrifying scenario. Like putting open doors into our brains
I’m sorry my answer triggered something; it wasn’t meant to. In my experience people here are nice and friendly, so I hope you manage to feel safe and welcomed.
What 😅? Ok I guess 😅
I was just saying it’s hard to make a company spend more “just” for the environment, but it’s still important to do.
I’m trying at mine and it goes exactly as you would think…

Thanks for being so responsive!
It seems that the problem is fixed now but the fix is not yet in upstream (should be soon).
In the study, physicians found more inaccuracies and irrelevant information in answers provided by Google’s Med-PaLM and Med-PalM 2 than those of other doctors.
It’s a bit like every other use of AI IMO: the challenge is to make people understand that it’s a fancy information retrieval system and thus it is flowed and not to be blindly trusted. There was study on the use of professional settings that showed that model such as ChatGPT helped low performers much more than high performers (which had barely any improvement thanks to the model). If this model is used to help less competent doctors (without judgement, they could be beginning their careers) while maintaining a certain degree of doubt, then that could be very good.
However, the ramification of a wrong diagnosis from the AI is quite scary, especially considering that AI tend to repeat the biais of their training dataset, and even curated data is not exempt from biais
I would advise not training your own model but instead use tools like langchain and chroma, in combination with a open model like gpt4all or falcon :).
So in general explore langchain!

Rocky Linux, AlmaLinux, and Oracle Linux for example.

True! My gf is a chemist and said that there used to be that saying that if you hadn’t had your Nobel by 35 then you failed :S
Also you don’t usually get a Nobel at the beginning of your career?
Make Indian food :D. It’s a gigantic country filled with vegetarians, they have some sick recipes :)






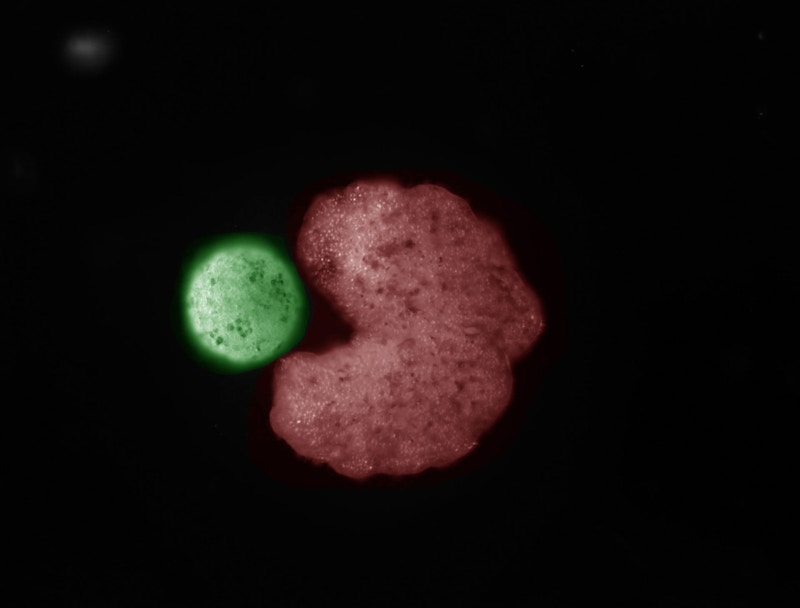



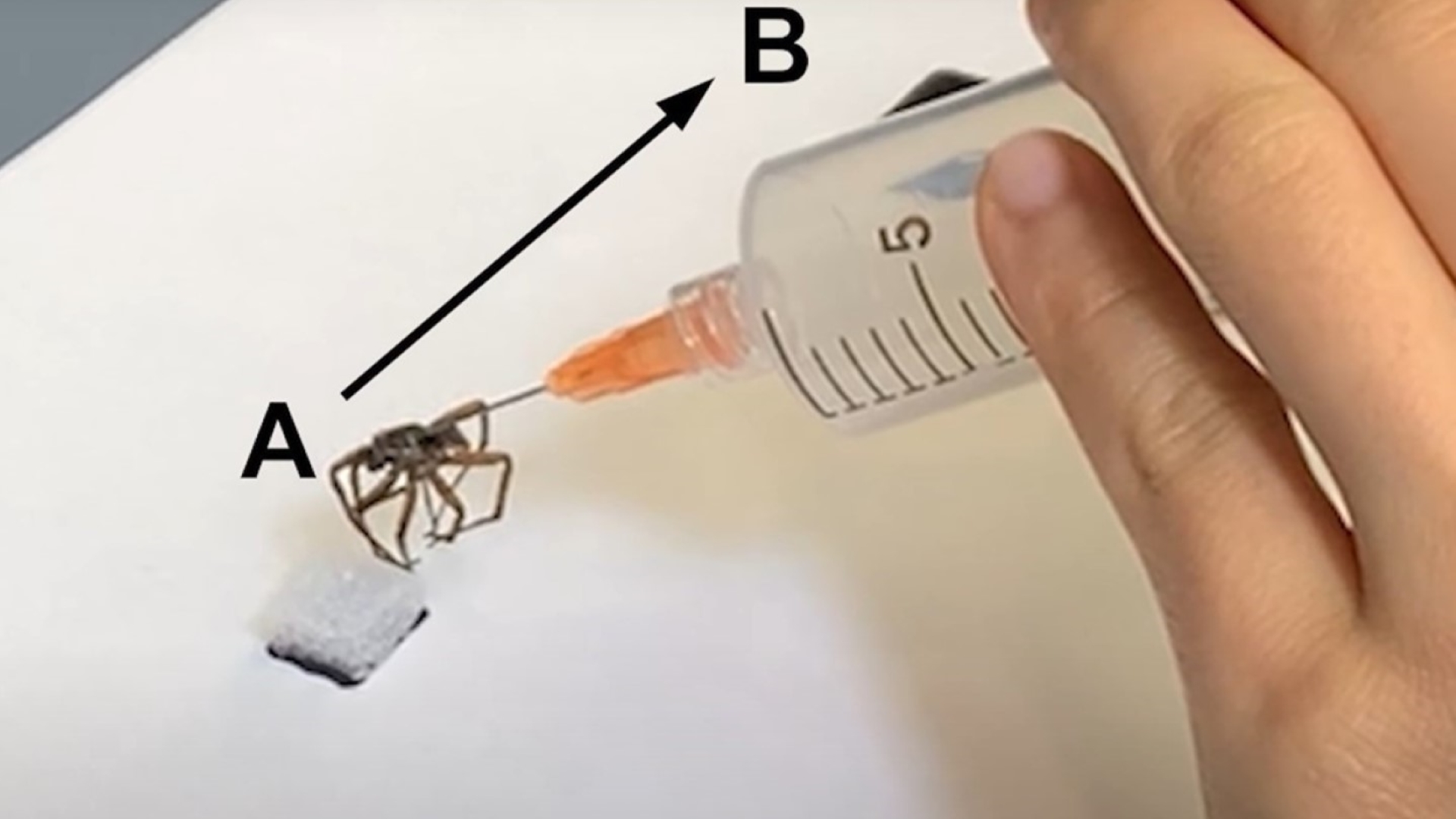


{kind=link}
{kind=link}
In the only loaf like picture I have it didn’t find my cat because it’s only her butt :(