I found that even when you can see the image, alt-text often helps significantly with understanding it. e.g. by calling a character or place by name or saying what kind of action is being done.
The one thing I’m uneasy about with these extremely detailed alt-text descriptions is that it seems like a treasure trove of training data for AI. The main thing holding back image generation is access to well-labelled images. I know it’s against ToS to scrape them but that doesn’t mean companies can’t, just that they shouldn’t. Between here and mastadon/etc there’s a decent number of very well-labelled images.
Honestly I think that sort of training is largely already over. The datasets already exist (have for over a decade now), and are largely self-training at this point. Any training on new images is going to be done by looking at captions under news images, or through crawling videos with voiceovers. I don’t think this is a going concern anymore.
And, incidentally, that kind of dataset just isn’t very valuable to AI companies. Most of the use they’re going to get is in being able to create accessible image descriptions for visually-disabled people anyway; they don’t really have a lot more value for generative diffusion models beyond the image itself, since the aforementioned image description models are so good.
In short, I really strongly believe that this isn’t a reason to not alt-text your images.
It sort of can. Firefox is using a small language model to do just that, in one of the more useful accessibility implementations of machine learning. But it’s never going to be capable of the context that human alt text, from the uploader, can give.
True, but I was thinking maybe something in the crate post flow(maybe running client side so as not to overload the lemmy servers 😅) that generates a description that the uploader can edit before(and after) they post it, that way it’s more effort for the poster to not add it than to add it, and if it’s incorrect people will usually post comments to correct it. Maybe also adding a note at the end that its ai generated unless the user edits it.
But that’s probably way too complicated for all the different lemmy clients to be feasible to implement tbh.
AI training data mostly comes from giving exploited Kenyans PTSD, alt-text becoming a common thing on social media came quite a bit after these AI models got their start.
Just be sure not to specify how many fingers, or thumbs, or toes, or that the two shown are opposites L/R. Nor anything about how clown faces are designed.

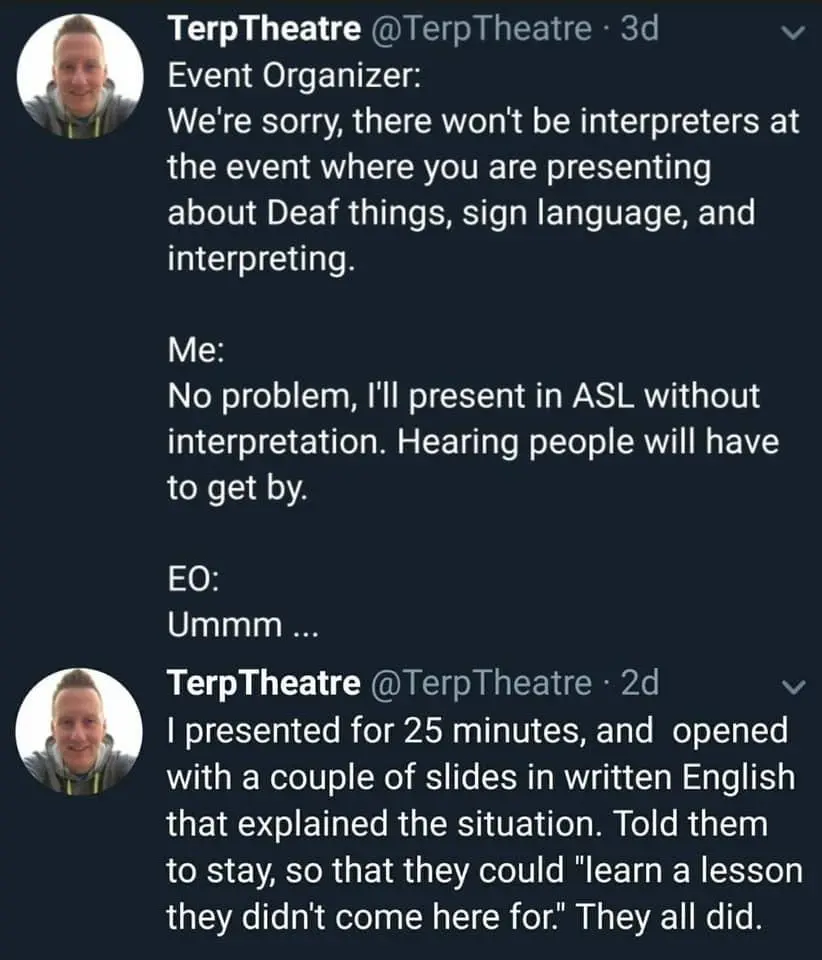{kind=link}
I found that even when you can see the image, alt-text often helps significantly with understanding it. e.g. by calling a character or place by name or saying what kind of action is being done.
The one thing I’m uneasy about with these extremely detailed alt-text descriptions is that it seems like a treasure trove of training data for AI. The main thing holding back image generation is access to well-labelled images. I know it’s against ToS to scrape them but that doesn’t mean companies can’t, just that they shouldn’t. Between here and mastadon/etc there’s a decent number of very well-labelled images.
I would gladly train a million AI robots just to make the web a lot cooler for those visual impairment.
The AI ship has already sailed. No need to harm real humans because somebody might train an AI on your data.
Honestly I think that sort of training is largely already over. The datasets already exist (have for over a decade now), and are largely self-training at this point. Any training on new images is going to be done by looking at captions under news images, or through crawling videos with voiceovers. I don’t think this is a going concern anymore.
And, incidentally, that kind of dataset just isn’t very valuable to AI companies. Most of the use they’re going to get is in being able to create accessible image descriptions for visually-disabled people anyway; they don’t really have a lot more value for generative diffusion models beyond the image itself, since the aforementioned image description models are so good.
In short, I really strongly believe that this isn’t a reason to not alt-text your images.
Maybe the AI can alt text it for us.
It sort of can. Firefox is using a small language model to do just that, in one of the more useful accessibility implementations of machine learning. But it’s never going to be capable of the context that human alt text, from the uploader, can give.
True, but I was thinking maybe something in the crate post flow(maybe running client side so as not to overload the lemmy servers 😅) that generates a description that the uploader can edit before(and after) they post it, that way it’s more effort for the poster to not add it than to add it, and if it’s incorrect people will usually post comments to correct it. Maybe also adding a note at the end that its ai generated unless the user edits it.
But that’s probably way too complicated for all the different lemmy clients to be feasible to implement tbh.
I think that would make a great browser extension. I’m not in a position to make it right now, but wow, that could potentially be really useful.
AI training data mostly comes from giving exploited Kenyans PTSD, alt-text becoming a common thing on social media came quite a bit after these AI models got their start.
Just be sure not to specify how many fingers, or thumbs, or toes, or that the two shown are opposites L/R. Nor anything about how clown faces are designed.
What do you think is creating all those descriptions?
It’s been great on pixelfed, I appreciate the people that put some time into it